
از هر 10 فرانسوی، 9 نفر حتی در مواجهه با یک آزمون ساده هم نمیتوانند اخبار جعلی را تشخیص دهند.

همزمان با گردش بیسابقه اطلاعات در رسانههای اجتماعی و پلتفرمهای دیجیتال، تشخیص واقعیت از خیال به طور فزایندهای پیچیده میشود. با وجود محتوای ویروسی، جعلهای عمیق تولید شده توسط گروک و تکثیر منابع، چشمانداز رسانه به سرعت در حال تکامل است.
اکثریت بزرگی از مردم فرانسه با اخبار جعلی دست و پنجه نرم میکنند
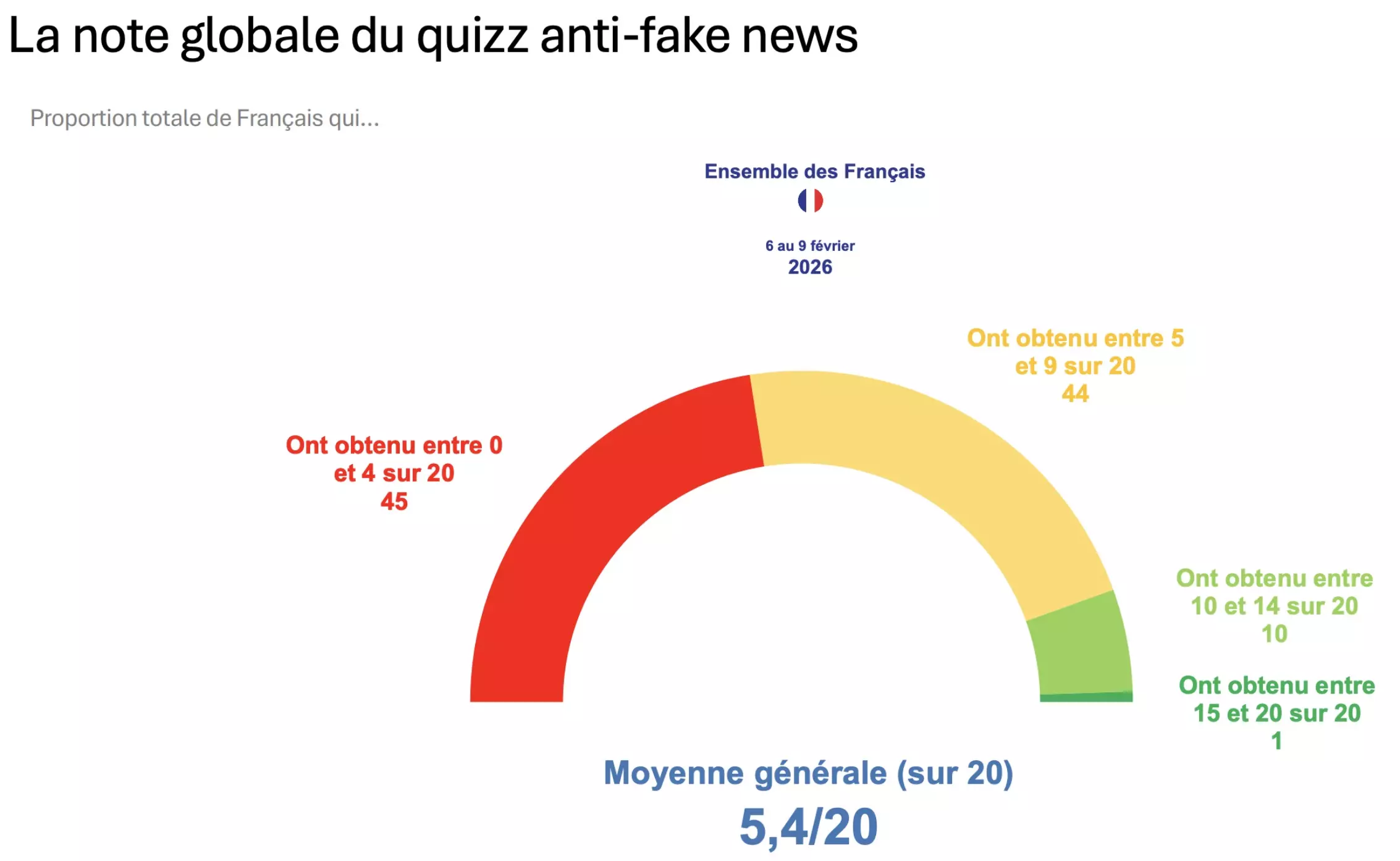
میانگین کلی بسیار نگرانکننده است – منبع: Ifop
بر اساس آزمونی به نام "ضد اخبار جعلی" که توسط روزنامهنگار توماس هوچون طراحی شده است، فرانسویها به طور متوسط نمره ۵.۴ از ۵ را کسب کردند. ۲۰. در واقع، ۸۹٪ از شرکتکنندگان به نمره متوسط نمیرسند و تنها ۱٪ از ۱۵ از ۲۰ فراتر میروند. این نتایج نشان میدهد اینکه تشخیص محتوای گمراهکننده برای اکثر شهروندان چقدر دشوار است. برخلاف برخی تصورات از پیش تعیینشده، این آسیبپذیری بر کل جامعه تأثیر میگذارد و دستههای اجتماعی، جهتگیریهای سیاسی یا حتی مناطق جغرافیایی به عنوان سدی واقعی در برابر اطلاعات نادرست عمل نمیکنند. همانطور که توماس هوچون اشاره میکند، "همه ما قربانیان بالقوه این پدیدهها هستیم." تفاوتها بر اساس سن، تحصیلات و استفاده از رسانههای اجتماعی: در حالی که این مشکل به طور گسترده مشترک است، این مطالعه چندین تفاوت را بسته به پروفایلهای فردی برجسته میکند. بنابراین، نسل Z با میانگین بین ۶.۳ تا ۶.۷ از ۲۰، کمترین نتایج ضعیف را کسب میکند، در حالی که نمرات به تدریج با افزایش سن کاهش مییابد. بنابراین افراد ۶۵ سال به بالا تقریباً ۴.۸ از ۲۰ را کسب میکنند. تحصیلات نیز نقش دارد، زیرا افراد دارای مدرک تحصیلات عالی به طور متوسط ۷.۶ از ۲۰ را کسب میکنند، در حالی که افراد بدون دیپلم دبیرستان ۴.۴ از ۲۰ را کسب میکنند. علاوه بر این، همانطور که یک نظرسنجی اروپایی نشان داد، به نظر میرسد استفاده از رسانههای اجتماعی یک عامل تعیینکننده است، به طوری که کسانی که کمتر از دو ساعت در روز را در رسانههای اجتماعی میگذرانند، به طور متوسط 5.6 امتیاز کسب میکنند، در حالی که این امتیاز برای کسانی که بیش از پنج ساعت در روز را صرف میکنند، 4.9 است. در نهایت، شیوههای اطلاعرسانی بر نتایج تأثیر میگذارند، زیرا مصرفکنندگانی که مرتباً به مطبوعات روزانه ملی مراجعه میکنند یا منابع اطلاعاتی خود را متنوع میکنند، نمرات کمی بالاتری کسب میکنند. هوش مصنوعی، شناسایی محتوا را پیچیدهتر میکند...
این مطالعه همچنین به یک مشکل رو به رشد مرتبط با ظهور هوش مصنوعی مولد اشاره میکند.
به عنوان مثال، یک سوال مسابقه مربوط به تشخیص چهرههای ایجاد شده توسط هوش مصنوعی بود. نتایج نشان میدهد که 97٪ از شرکتکنندگان پاسخ نادرست یا ناقصی ارائه دادهاند. این رقم، پیچیدگی فزایندهی تشخیص محتوای مصنوعی از تصاویر معتبر را نشان میدهد.
این تحول همچنین مسائل اقتصادی را مطرح میکند، زیرا تخمین زده میشود که اطلاعات نادرست تا سال ۲۰۲۴ بیش از ۴۰۰ میلیارد دلار هزینه در سراسر جهان ایجاد خواهد کرد.
در مواجهه با این روند، در زمانی که ابزارهای تولید محتوا پیچیدهتر میشوند، توانایی تجزیه و تحلیل اطلاعات اکنون به عنوان یک مهارت مستقل در حال ظهور است...
لطفا ورود به سیستم برای گذاشتن نظر
می خواهید موضوع خود را ارسال کنید
به جامعه جهانی سازندگان بپیوندید، از محتوای خود به راحتی درآمد کسب کنید. امروز سفر درآمد غیرفعال خود را با Digbly شروع کنید!
اکنون آن را ارسال کنید
نظرات